- Django installation with pip.
- Install Django with virtualenv.
- Install Django fron it's github repository.
Django is a web application framework written in python that follows the MVC (Model-View-Controller) architecture, it is available for free and released under an open source license. It is fast and designed to help developers get their application online as quickly as possible. Django helps developers to avoid many common security mistakes like SQL Injection, XSS, CSRF and clickjacking. Django is maintained by the Django Software Foundation and used by many big technology companies, government, and other organizations. Some large websites like Pinterest, Mozilla, Instagram, Discuss, The Washington Post etc. are developed with Django.
Prerequisites
- Ubuntu 16.04 - 64bit.
- Root privileges.
Step 1 - Setup python 3 as Default Python version
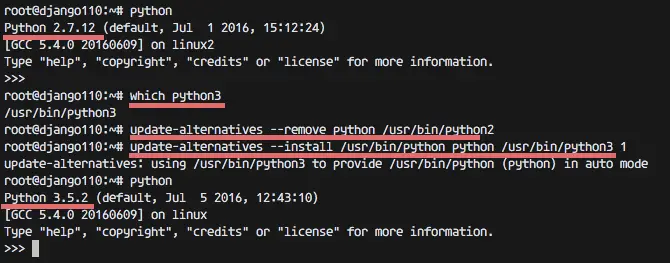
We will configure python 3 before we start with the Django installation.On my Ubuntu machine, there are two versions of python available, python2.7 as default python version and python3. In this step, we will change the default python version to python 3.
Check the python version:
python
Result:
python
Python 2.7.12 (default, Jul 1 2016, 15:12:24)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>
So the default python is 2.7 at the moment.Python 2.7.12 (default, Jul 1 2016, 15:12:24)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>
Next, remove default python 2 and change the default to python 3 with the 'update-alternatives' command:
update-alternatives --remove python /usr/bin/python2
update-alternatives --install /usr/bin/python python /usr/bin/python3
Now check again the python version:update-alternatives --install /usr/bin/python python /usr/bin/python3
python
Result:
python
Python 3.5.2 (default, Jul 5 2016, 12:43:10)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
Python 3.5.2 (default, Jul 5 2016, 12:43:10)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
Step 2 - Install Django
In this step, I will show you 3 ways to install Django. Please follow either chpater 2.1, 2.2 or 2.3 to install Django but not all 3 options at the same time :)2.1. Install Django with Pip
Pip is a package management system for python. Python has a central package repository from which we can download the python package. It's called Python Package Index (PyPI).In this tutorial, we will use python 3 for django as recommended by the django website. Next, we will install pip for python 3 from the ubuntu repository with this apt command:
apt-get install python3-pip
The installation will add a new binary file called 'pip3'. To make it
easier to use pip, I will create a symlink for pip3 to pip:
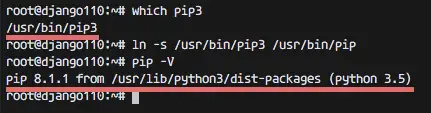
which pip3
ln -s /usr/bin/pip3 /usr/bin/pip
Now check the version :ln -s /usr/bin/pip3 /usr/bin/pip
pip -V
The pip installation is done. Now we can use the pip command to install python packages. Let's install django on our server with pip command below:
pip install django==1.10
Note:We set django==1.10 to get a specific version. If you want a different version, just change the number e.g. to django==1.9 etc.
If you have an error about the locale settings, run the command below to reconfigure the locale settings:
export LANGUAGE=en_US.UTF-8
export LANG=en_US.UTF-8
export LC_ALL=en_US.UTF-8
locale-gen en_US.UTF-8
dpkg-reconfigure locales
When the installation is done, check the django version with the command below:export LANG=en_US.UTF-8
export LC_ALL=en_US.UTF-8
locale-gen en_US.UTF-8
dpkg-reconfigure locales
django-admin --version
Alternatively, we can use command below:
python
import django
print(django.get_version())
import django
print(django.get_version())
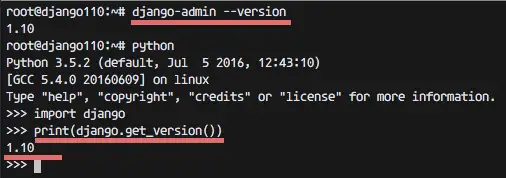
Django 1.10 has been installed on the system with pip. Proceed with chapter 3.
2.2. Install Django with Virtualenv
Virtualenv is a python environment builder, it is used to create isolated python environments. We can choose the version of python that will be install in the virtualenv environment. This is very useful for developers, they can run and develop an application with different python versions and different environments on one OS.Virtualenv is available on PyPI, we can install it with the pip command:
pip install virtualenv
Now we can use the virtualenv command to create a new environment
with python3 as default python version. So let's create a new
environment "mynewenv" with python3 as the python version and pip3 for
the django installation.
virtualenv --python=python3 mynewenv
Note : --python=python3 is a binary file for python 3.
mynewenv is the name of the environment.
The command will create a new directory called 'mynewenv' which contains the directories bin, include and lib.
The virtualenv has been created, now let's log into the new environment with the command below:
source mynewenv/bin/activate
If you do not have the source command, you can run this command instead:
. mynewenv/bin/activate
Note: If you want to get out from the virtual environment, use the command 'deactivate'.Now check the pip version:
pip -V
Pip will be automatically installed inside the virtual environment.Next, install django in thevirtual environment that we've created:
pip install django==1.10
When the installation finished, check the Django installation:
django-admin --version
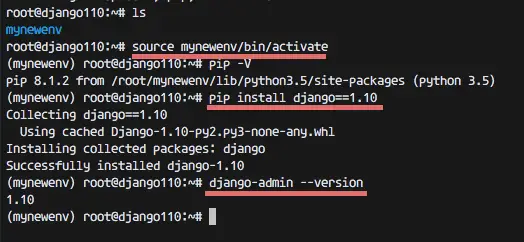
Django 1.10 has been successfully installed inside our virtual environment. Proceed with chapter 3.
2.3. Install Django from Git Repository
In this chapter, we will install the Django web frame work inside the system, not in a virtual environment. I will show you how to install it manually from the Django Git repository. Make sure you have git installed on your server. If you don't have git, install it with the command below:
apt-get install git -y
Next, create a new python virtual environment and activate it:
virtualenv --python=python3 django-git
source django-git/bin/activate
Then clone the django git repository with the command below:source django-git/bin/activate
cd django-git
git clone git://github.com/django/django django-dev
Install django with this pip command:git clone git://github.com/django/django django-dev
pip install -e django-dev/
-e = Install a package in editable mode or a local package.
In this chapter, we install Django from the local code that we've
cloned.When the installation process is done, let's check the Django version on the server:
django-admin --version
1.11.dev20160831163130
We see the django 1.11 dev version.1.11.dev20160831163130
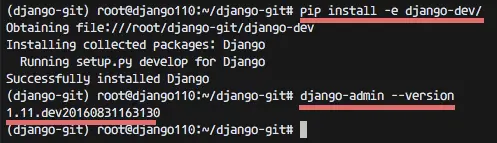
The manual Django installation is finished.
Step 3 - Create you First Project with Django
In this step, we will install django inside a virtual environment and then start our first project with django.Install virtualenv on the server and create a new environment named 'firstdjango' :
pip install virtualenv
virtualenv --python=python3 firstdjango
Now go to the firstdjango directory and activate the virtual envonment, then install django with the pip command:virtualenv --python=python3 firstdjango
cd firstdjango/
source bin/activate
pip install django==1.10
Next, create a new project called 'myblog' with the django-admin command:source bin/activate
pip install django==1.10
django-admin startproject myblog
It will create a new directory myblog that contains the django files:
ll myblog
-rwxr-xr-x 1 root root 249 Sep 06 09:01 manage.py*
drwxr-xr-x 2 root root 4096 Sep 06 09:01 myblog/
Go to the myblog directory and run the 'manage.py' file :-rwxr-xr-x 1 root root 249 Sep 06 09:01 manage.py*
drwxr-xr-x 2 root root 4096 Sep 06 09:01 myblog/
cd myblog/
python manage.py runserver
The runserver option will create a HTTP connection with
python on localhost IP and port 8000. If your development environment is
on a separate server, as in my example here I'm using an Ubuntu server
with I : 192.168.1.9, you can use the server IP so you can access Django
from outside of the server.python manage.py runserver
python manage.py runserver 192.168.1.9:8000
Now check from your browser: 192.168.1.9:8000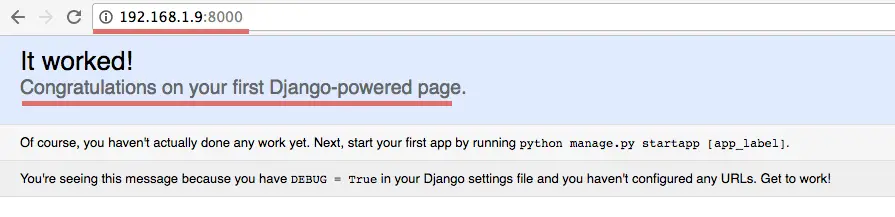
The Django default page is working and inside the server, you can look at the access log:
[31/Aug/2016 17:04:40] "GET / HTTP/1.1" 200 1767Next, we will configure the Django admin. Django will automatically generate the database for a superuser. Before we create the superuser, run the command below:
python manage.py migrate
migrate: make adds the models (adding fields, deleting etc.) into the database scheme, the default database is sqlite3.Now create the admin/superuser:
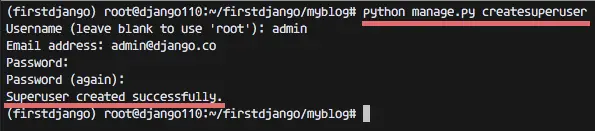
python manage.py createsuperuser
Username (leave blank to use 'root'): admin
Email address: admin@mydjango.co
Password:
Password (again):
Superuser created successfully.
Username (leave blank to use 'root'): admin
Email address: admin@mydjango.co
Password:
Password (again):
Superuser created successfully.
The Django super user has been added, now you can execute the runserver command, then go to the browser and visit the django admin page:
python manage.py runserver 192.168.1.9:8000
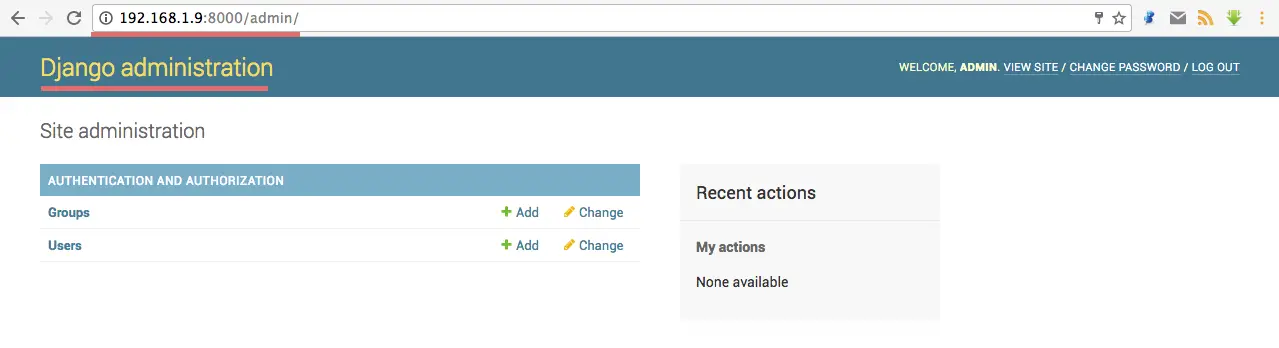
Visit Django admin page: 192.168.1.9:8000/admin/. Login with username admin and your password, you will see the admin page:Django admin login page.
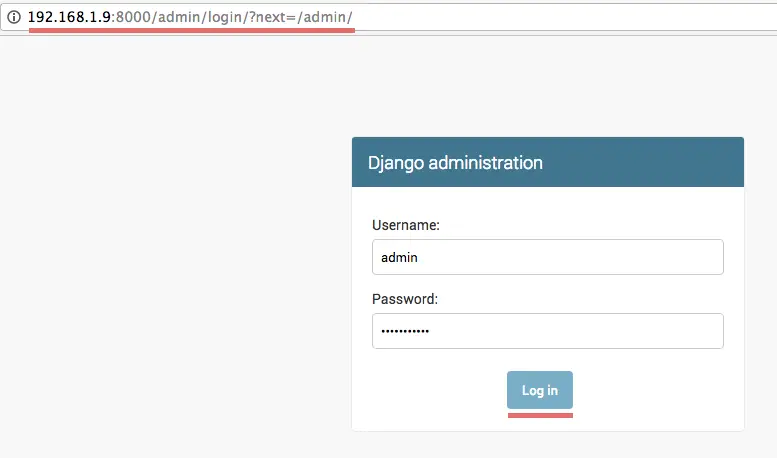
The Django admin dashboard.
Django has been successfully installed inside a virtual environment and we've created a sample Django project named 'firstdjango'.



